Five years ago, Arm announced its Neoverse program for server, cloud and infrastructure CPU cores. The company has redoubled its efforts to make a big push into the infrastructure CPU market, laying out an ambitious multi-year plan to develop a triple lineup of CPU cores to cater to different segments of the market – starting with the powerful V-series at its core, and the petite E-series at its core. Series is the core. While things have turned out slightly differently than Arm originally expected, they have little to complain about, as the Neoverse line of CPU cores has never been more successful. Custom CPU designs based on Neoverse cores have become extremely popular among cloud providers, and the broader infrastructure market has seen its own surge.
Now, as the company and its customers pivot to 2024, where the computing market is in the throes of another transformation due to growing demand for AI hardware, Arm is preparing to release its next-generation Neoverse CPU core design to customers. In the process, the company is reaching the culmination of its original Neoverse roadmap.
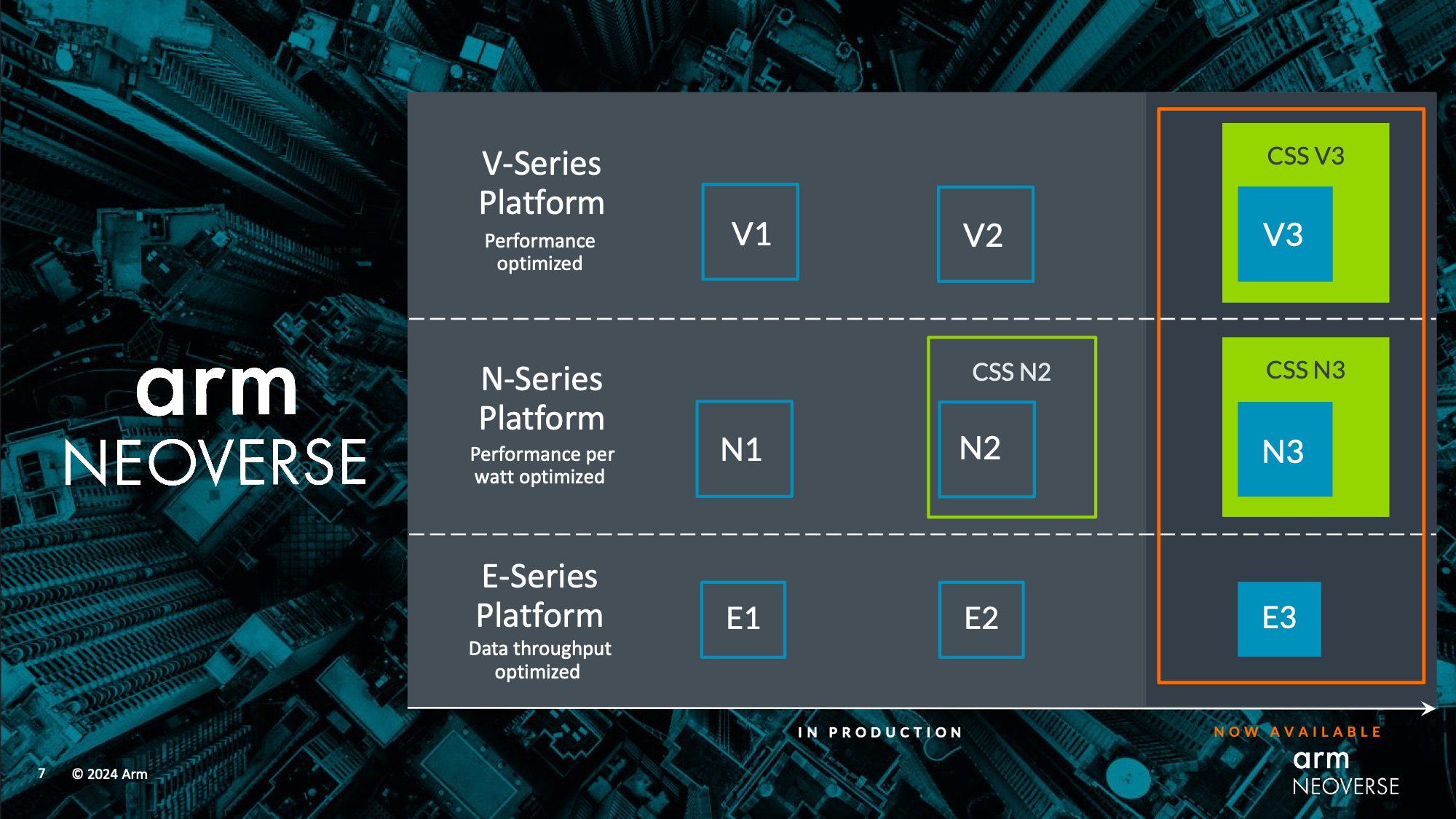
This morning, the company took the wraps off its V3 CPU architecture (codenamed Poseidon) for high-performance systems and its N3 CPU architecture (codenamed Hermes) for balanced systems. These designs are now available for customers to begin integrating into their own chip designs, with both individual CPU core designs available as well as larger Compute Subsystems (CSS). Between the various combinations of IP configurations, Arm hopes to offer something for everyone, especially chip designers looking to integrate off-the-shelf IP to develop their own chips with a quick turnaround.
That being said, it should be noted that today’s announcement is also lighter than what we’ve come to expect from Neoverse’s previous announcements. Arm didn’t release any deep architectural details of the new Neoverse platform today, so while we have high-level details of the hardware and some basic performance estimates, the low-level details of the CPU cores and their associated pipelines are Arm’s stuff until a later time. .
Neoverse V3: Up to 128 cores, using CXL 3.0 and HBM3, plus CSS design
First, start with the high-end architecture V3 CPU core of the Neoverse platform. Neoverse V3 was previously listed as “V-Next” in Arm’s roadmap, codenamed Poseidon. It was the final architectural design in Arm’s original Neoverse roadmap, and Arm would finally realize what they envisioned long ago.
Neoverse V cores have traditionally been derived from Cortex-X designs, and while Arm isn’t revealing this level of detail at the moment, there’s no reason to believe that’s changed. I suspect the CPU core design we’re looking at borrows heavily from the Cortex-X5 (Arm’s next-generation Cortex-X design) to align with the use of X1 and X3 in V1 and V2 respectively. But that’s certainly an assumption on my part.
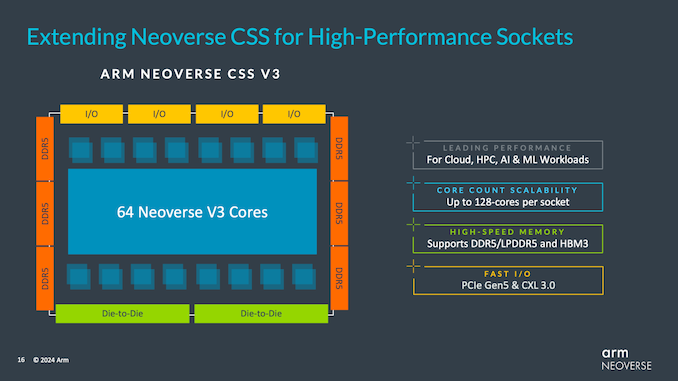
Regardless, like previous V-series CPU cores, V3 is targeted at the highest performance applications, delivering the highest single-threaded performance of any Arm Neoverse CPU core. With up to 64 cores on a single chip and two chips/128 cores on a single socket, V3 is designed to compete at the high end like the V2 before it.
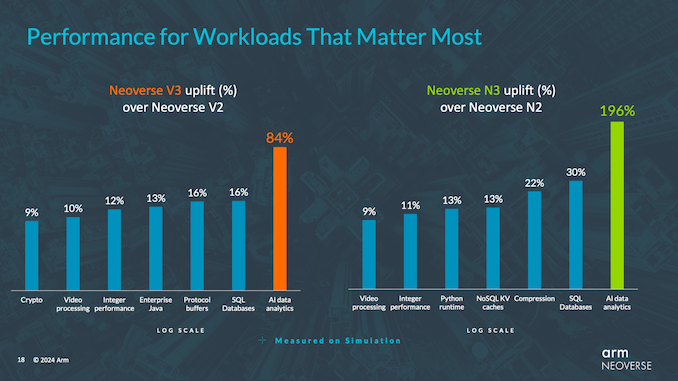
Arm has not provided general performance estimates for CPU cores, but in simulations they found performance between 10% and 20% for most workloads, except for the edge case of AI data analysis (emphasis on “analytics” rather than “artificial intelligence” ). Going back to Arm’s earliest roadmaps, this was less than their original goal of 30% generation-by-generation improvement, but then again, V2 wasn’t even on those roadmaps at the time, so Arm’s pace became smaller and smaller. More often.
Again, we don’t have any in-depth architectural details here, but we do have some high-level details of the changes that V3 brings. Arm, for example, is focusing a lot of effort on mesh fabrics in several ways. The V3 itself has improved connections to the Arm mesh fabric to relieve pressure there. The mesh itself is new, replacing Arm’s tried-and-true CMN-700 with the new CMN-S3 – although we don’t have any further details on the latter.
Otherwise, V3 and its CSS counterpart support all the latest I/O and memory formats. CXL support has been upgraded from CXL 2.0 to CXL 3.0 via I/O – still on top of PCIe 5.0. At the same time, in terms of memory, LPDDR5, DDR5 and HBM3 all support Arm’s IP.
For the first time, Arm is offering an off-the-shelf CSS version of this IP for V-Series CPU cores for rapid integration into customer silicon designs. While the CSS initiative itself is still fairly new, Arm said the strategy has proven highly successful, with hungry and well-funded cloud providers like Microsoft (Cobalt 100) quickly adopting it to quickly integrate their own chip designs, hardware Put into use. So Arm wants to bring the same level of simplicity to high-performance customers, especially those who just need proven CPU IP blocks to pair with their custom accelerator designs, and Arm even offers a set of off-the-shelf chip-to-chip connections to simplify further process.
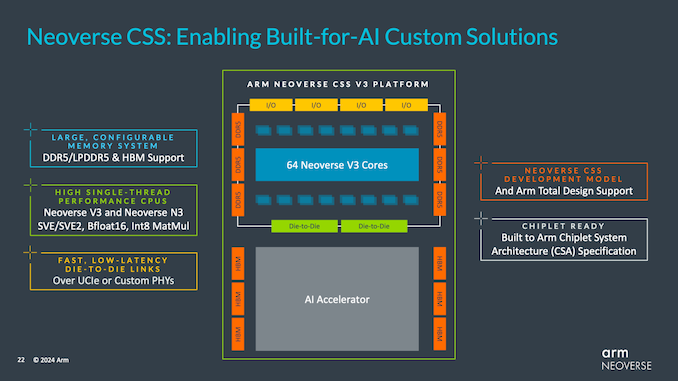
Although it was technically announced earlier this month, the V3 CSS design is closely tied to Arm’s efforts to build its own chiplet ecosystem – the Arm Chiplet System Architecture (CSA). Designed to make it easier for customers to mix and match chiplets in their products, the CSA program goes beyond protocol compatibility to address issues such as system management, DMA, security and software compatibility.

Finally, to underscore the rapid turnaround time Arm envisions for its V3 CSS IP, the company has announced a design win from Socionext, which is designing a 32-core V3 CSS chiplet that will be produced at Taiwan Semiconductor Manufacturing Co., Ltd. (TSMC).
Arm Neoverse N3: 20% better performance per watt, up to 32 cores
Another part of today’s Neoverse IP announcement is Neoverse N3 (codenamed Hermes), the latest in Arm’s family of balanced, energy-efficient CPU cores for a variety of markets.

Focusing more on their CSS IP this time, N3 CSS is designed to support a range of CPU cores, from 8 to 32. For the latter, Arm says their design can run with as low as a 40W TDP, or just over 1 watt per CPU core – although the company didn’t reveal what process node this is.
Overall, Arm claims that the performance per watt of N3 CSS is an average of 20% higher than that of N2 CSS. Overall performance improvements typically range from 10% to 30%, depending on the specific workload.
As with V3, Arm doesn’t provide many architectural details here. But since N-series designs have historically shared a lot of design elements with the Cortex-A7xx series, I wouldn’t be surprised to eventually find that the N3 has the same design elements as well.
At the same time, Arm briefly introduced the internals of N3 CSS to explain its huge performance leap in AI data analysis based on the XGBoost library.
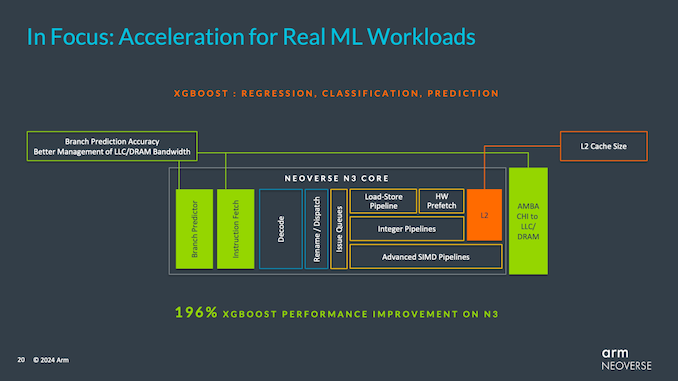
First, N3 CSS’s L2 cache size is now 2MB per core, compared to N2’s L2 cache size of 1MB. In fact, Arm has also spent considerable effort on its overall cache and memory subsystem, including making some undisclosed tweaks to its consistent host interface to better manage CPU cores and last-level cache (and more). high level) between traffic and memory bandwidth. . Although it’s unclear whether the N3 also uses Arm’s new CMN-S3 mesh, or if it’s limited to the V3. At the same time, on the front end of N3, the CPU core has a more accurate branch prediction unit.
Altogether, these improvements and more improve Arm’s XGBoost performance by 196%, and similarly, the V3 CPU core’s performance improves by 84% under the same workload. This makes Data Analytics/XGBoost an extreme outlier overall, but it does show that Arm is putting some effort into its upcoming generation of CPU architecture.
In addition to these core improvements, N3 also features many of the I/O and memory improvements that V3 also received. Arm hasn’t provided a detailed list yet, but we’re told it supports the latest PCIe and CXL standards – which are likely PCIe 5.0 and CXL 3.0 respectively. It is worth noting that Arm’s previous roadmap has fixed this generation of hardware to support PCIe 6.0, but since it has not entered V3, it seems that Arm has to take a step back.
Finally, like V3 CSS, N3 CSS also has chip-to-chip interconnect capabilities. Although like most other aspects of N-Series hardware, it’s been reduced to a single interconnect. Therefore, chip vendors can choose to integrate N3 directly into their chip designs or connect it to an external accelerator chiplet.
Looking ahead: Adonis, Dionysus and Lysius
Finally, with Arm’s current Neoverse roadmap coming to an end, the company is providing a roadmap for future CPU core releases.
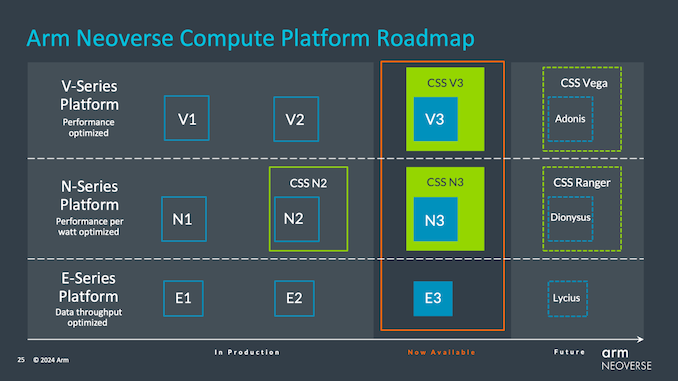
It’s worth noting that this is a less detailed roadmap than Arm’s V2/N2 era roadmap, which includes some high-level descriptions of what technologies are expected to emerge. Instead, the roadmap only provides code names and nothing more.
With confirmation that Arm is working on fourth-generation versions of its E, N, and V CPU cores, we have a few new codenames overall. Lycius will be the next Neoverse E-series core (E4?), while Dionysus will be the next N-series core and Adonis the next V-series core. At the same time, their respected computing subsystems also received codenames, CSS Ranger and CSS Vega for N-series CSS and V-series CSS, respectively.
At this time, Arm is not providing any guidance on when these designs will be ready for customers. But with V3/N3 IP just launched to customers, the fourth generation of Neoverse IP may appear in a few years.