AnandTech Live Blog: Latest updates at the top. The page updates automatically, no need to refresh the browser manually.

05:11 PM ET – Now introducing Earth-2, NVIDIA’s simulation for AI-driven weather forecasting and climatology
05:10 PM (ET) – (We have now moved to software)
05:09 PM (ET) – “Anything that can be digitized, as long as there are patterns, you can learn from it”

05:08 PM ET – Artificial intelligence is changing the way software is written.Instead of writing code to teach a computer to recognize cats, create an AI model and train it to recognize cats
05:07 PM (ET) – Review of Alexnet 2012, identifying cats
05:06 PM ET – “This is what happens when you don’t rehearse”

05:05 PM ET – That’s Wistron
05:05 PM ET – Digital twins enable them to test operations and find ways to improve
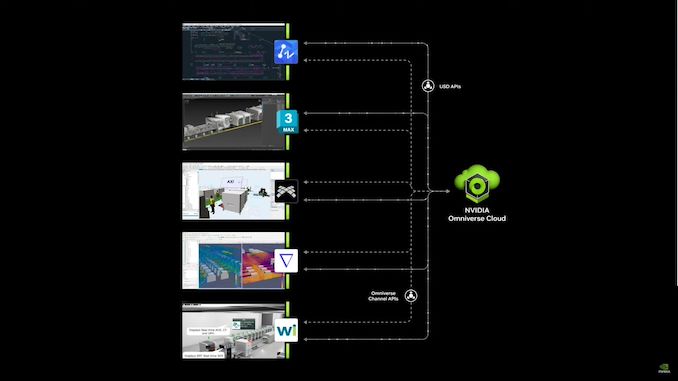
05:04 PM (ET) – Now let’s demonstrate one of NV’s partners, Wistron, which is using NVIDIA’s technology to build a digital twin of its factory


05:02 PM (ET) – AWS, Google/GCP, Microsoft/Azure, Oracle have all joined


05:00 PM ET – NVIIDA started with just two clients and now has many:
04:59 PM ET ——”This ability is super, super important”
04:58 PM ET – This is where FP4 and NVLink switches come in
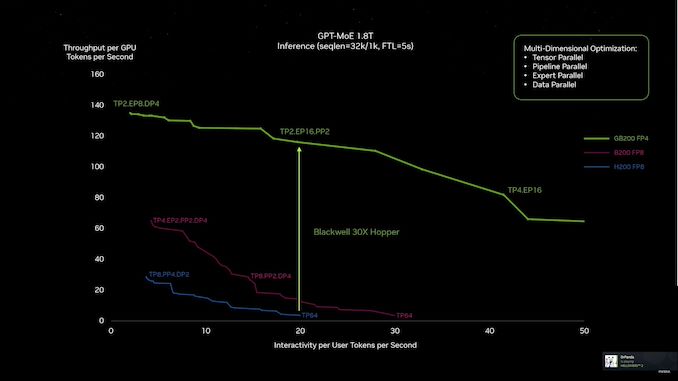
04:57 PM (ET) – Now watch Blackwell vs Hopper
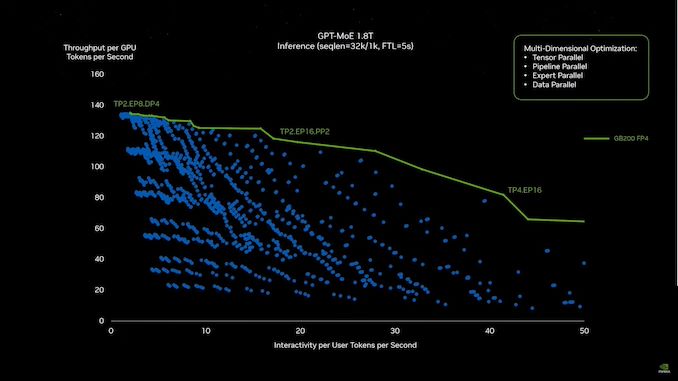
04:54 PM (ET) – Throughput is everything.

04:52 PM (ET) – Due to the size of the LL.M., its extrapolation is a challenge. They are not suitable for a single GPU
04:51 PM (ET) – GB200 NVL72 can be completed on 2000 GPUs with 4MW power

04:51 PM (ET) – Training GPT-MoE-18.T takes 90 days on an 8000 GPU GH100 system consuming 15W

04:50 PM ET – Weight: 3000 lbs (Premium, more lbs)

04:48 PM EST – Saved 20kW of calculation time
04:48 PM EST – These are copper cables.No optical transceiver required
04:48 PM EST – 5000 NVLink cables. 2 miles of cable

04:47 PM (ET) – 1 EFLOPS of FP4 in one rack
04:47 PM (ET) – This gives FP8 throughput of GB200 NVL 720 PFLOPS (spare)
04:46 PM ET – 9 NVSwitch racks
04:46 PM ET – 18 GB200 node racks, 2 GB200 per node

04:46 PM ET – Help NVIDIA build DGX GB200 NVL72
04:45 PM ET – Connect a GPU to act as a giant GPU

04:44 PM ET – There is also a new NVLink chip. 50B transistor, built on TSMC 4NP
04:44 PM EST – But why stop there?

04:43 PM ET – Hopper’s reasoning/token generation capabilities increased by 5x
04:42 PM (ET) – “The future is generative”

04:41 PM (ET) – FP4 gain is even greater since Hopper itself cannot handle FP4
04:41 PM (ET) – At the same time, the performance of FP8 is 2.5 times that of Hopper
04:40 PM ET – New feature: FP4 support. And FP6


04:40 PM ET – Blackwell also added a line decompression engine that can sustain 800GB/sec transfer
04:39 PM ET – Security remains a hot topic. Protecting the results of model training is to protect the model itself.This means full-speed encryption is supported throughout
04:38 PM EST – So NVIDIA added a RAS engine that can perform complete in-system self-test of nodes
04:38 PM EST – Jensen also emphasized the importance of reliability.No large cluster can stay running 100% of the time, especially for weeks on end

04:36 PM EST – 5th generation NVLink
04:36 PM EST – Supports as low as FP4
04:36 PM EST – Artificial intelligence is about probability.Need to figure out when lower precision can be used and when not

04:35 PM ET – Automatically and dynamically re-convert number formats to lower precision if possible
04:35 PM ET – Second generation transformer engine
04:35 PM ET – “We need a lot of new features”
04:34 PM EST – “But there’s more!”
04:34 PM EST – That’s Grace Blackwell

04:34 PM ET – NVLink on top, PCIe Gen 6 on bottom
04:34 PM ET – “This is a miracle”

04:33 PM EST – GB200 is memory consistent

04:33 PM EST -GB200. 1 Grace CPU + 2 Blackwell GPU (4 GPU chips)

04:33 PM EST – Jensen shows Blackwell boards…and tries not to drop them

04:32 PM ET – This chip is suitable for both types of systems. B100, designed to be directly compatible with H100/H200 HGX systems

04:31 PM ET – No memory locality issues or caching issues. CUDA treats it as a single GPU
04:31 PM ET – 10TBps link between chips

04:30 PM ET – “You’re good. Good girl.”

04:30 PM EST – “It’s okay, Hopper”

04:30 PM ET -Hold the Blackwell next to the GH100 GPU
04:29 PM ET – “Blackwell is not a chip. It is the name of a platform”

04:29 PM ET – NVLink 5 scales up to 576 GPUs
04:29 PM ET – NVDIA is building rack-scale products using GB200 and new NVLink operation GB200 NVL72


04:28 PM ET – NVLink 5. Equipped with new switch chip

04:28 PM ET – Can be used as accelerator and Grace Blackwell super chip

04:27 PM (ET) – 1.8TB/sec NVLink bandwidth per chip
04:27 PM (ET) – 192GB HBM3E@8Gbps

04:27 PM (ET) – 208B transistor
04:27 PM (ET) – Two chips on one package, fully cache coherent
04:27 PM (ET) – Scroll video now
04:27 PM (ET) – Named after mathematician and game theorist David Backwell
4:26 PM (ET) – This is Blackwell. “A really, really big GPU”
4:26 PM (ET) – “We’re going to have to build bigger GPUs”

04:24 PM (ET) – “We need a bigger model”
04:23 PM (ET) – To help the world build these larger systems, NVIDIA must build them first
04:23 PM (ET) – and developing technologies such as NVLink and Tensor Core

04:22 PM ET – The answer is to put a bunch of GPUs together
04:22 PM ET – “We need a bigger GPU” “A bigger GPU”

04:22 PM ET – Even PetaFLOP GPU takes 30 billion seconds to train this model.That was 1000 years
04:21 PM (ET) – The 1.8T parameter is the largest model currently.This requires billions of tokens to train
04:21 PM (ET) – Doubling the number of parameters requires increasing the number of tokens
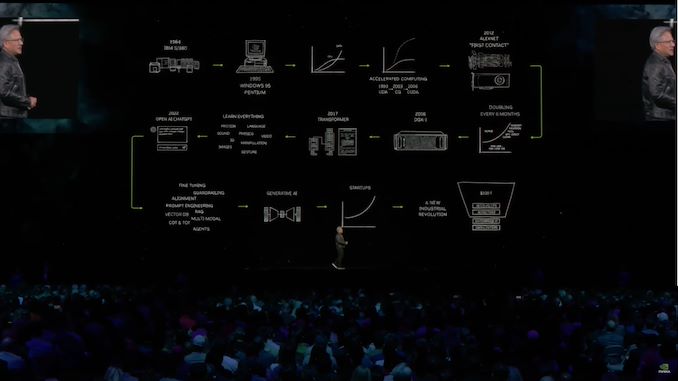
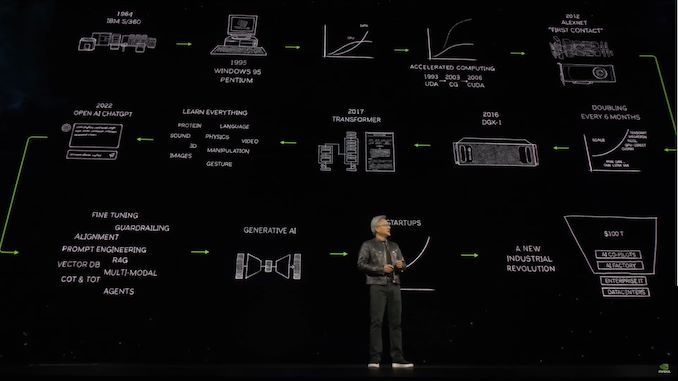
04:20 PM EST – Now looking back at the history of large language models and the hardware that drives them
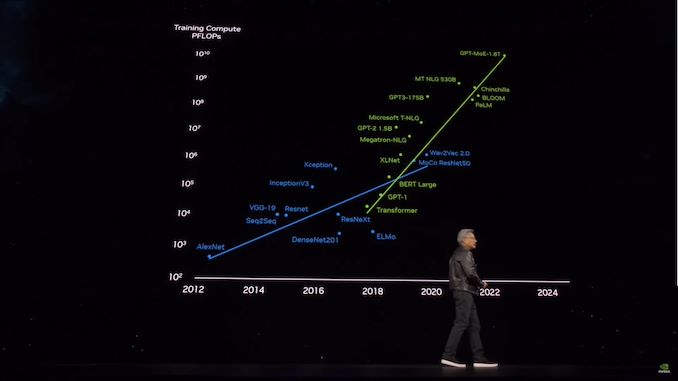
04:20 PM EST – Omniverse will become the basic operating system for digital twins
04:20 PM ET – Connect Cadence’s digital twin platform to Omniverse
04:19 PM ET – EDA tool maker Cadence also joins the GPU club

04:18 PM EST – TSMC announced today that they will be using cuLitho for production

04:18 PM EST – Accelerated computational lithography
04:18 PM EST – Sysopsys. NVIDIA’s first software partner.literally

04:17 PM EST – ANSYS
04:17 PM EST – Jensen will announce several key partnerships
04:17 PM EST – NVIDIA partners joining today
04:16 PM EST – Jensen wants to simulate everything they do in a digital twin virtual environment

04:16 PM ET – It’s not about reducing costs, it’s about increasing scale
04:15 PM ET – New methods are needed to keep computing growing.Continue to consume calculations
04:15 PM ET – “General purpose computing has run out of steam”

04:15 PM ET – NVIDIA’s GPUs are worth using because of the software written for them.Therefore, NVIDIA has always attached great importance to showcasing the latest developments in the software development community.
04:14 PM EST – (As far as I know, the concert capacity of SAP Arena is 18,500 people. With this floor layout, the capacity here may be more than that)
04:13 PM ET – Morphing, PhysX Flow, Photoshop and more

04:13 PM ET – Rolling demo volumes for GPU-accelerated applications
04:12 PM ET – “Everything is homemade”
04:12 PM ET – “It’s being animated using robotics. It’s being animated using artificial intelligence”
04:11 PM ET – Everything we show today is a simulation, not an animation
04:11 PM ET – and software and applications for the industry.and how to start preparing for the next step

04:11 PM ET – “We’re going to discuss how to do the calculations next”
04:10 PM ET – Generative AI compared to the Industrial Revolution and the Energy Age
04:09 PM ET – “This software has never existed before, it is a completely new category”
04:09 PM ET – 2023: Generative AI emerges and new industries begin
04:09 PM ET – CUDA finally succeeded.A little later than Jensen wanted.
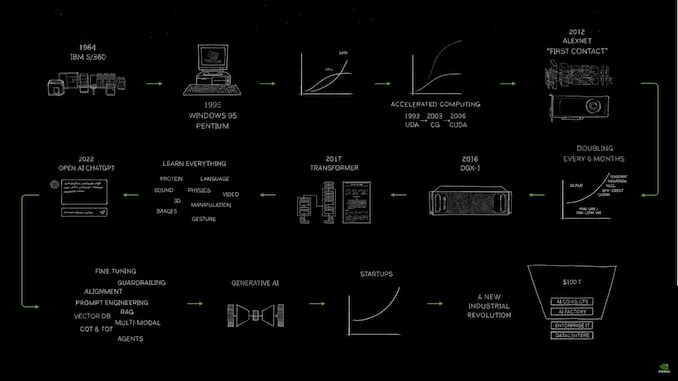
04:07 PM (ET) – How did we get here? Jensen drew a comic flow chart

04:07 PM (ET) – “The computer is the most important tool in today’s society”
04:06 PM EST – Display the list of exhibitors.This is a very big list

04:05 PM ET – Jensen is reviewing many of the techniques seen here. “Even artificial intelligence”
04:04 PM (ET) – “I suddenly felt a heavy weight in the room”

04:04 PM (ET) – “This is not a concert. You’ve come to a developer conference”
04:04 PM (ET) – Without further ado, this is Jensen
04:04 PM (ET) – This is Ryan.Sorry for the late start folks, it’s a fun time for everyone to sit back and get settled in

We’re in sunny San Jose, California for the long-awaited return of an event: NVIDIA Live GTC. The Spring 2024 event is NVIDIA’s annual event and will be a big deal for NVIDIA as the company will release updates to its most important data center accelerator products – the GH100 GPU and its Hopper architecture successor – as well as NVIDIA’s Additional professional/enterprise hardware, networking equipment, and of course a host of software stack updates.
A lot has changed for the company in the five years since NVIDIA last hosted Spring GTC in person. They are now the third largest company in the world, thanks in large part to explosive sales growth (and even further growth expected) thanks in large part to the combination of GPT-3/4 and other Transformer models, as well as the NVIDIA Transformer-optimized H100 accelerator. . So, NVIDIA’s position in Silicon Valley is strong, but to continue this momentum, they also need to launch the next big product that pushes the envelope of performance and keeps many hungry competitors at bay.
Headlining today’s keynote was, of course, NVIDIA CEO Jensen Huang, whose kickoff speech ultimately extended beyond the confines of the San Jose Convention Center. As a result, Huang filled the vacancy at the local SAP center.Arguably, this is a bigger venue that can accommodate more spectators [i]a lot of[/i] Bigger companies.
So join the AnandTech team for our live blog coverage of NVIDIA’s biggest corporate keynote in years. The presentation will begin at 1:00 PM Pacific Time, 4:00 PM Eastern Time, and 20:00 UTC.